由于标题长度限制,原题是这样:某系统QPS100万,每十分钟统计一下请求次数最多的100个IP。ip请求写到日志的话,其实就是超大文件中统计top k问题。10分钟6亿条记录,大约是10G级别,所以对于一般单机处理来讲不能一次性加载到内存计算。所以分治算法是处理这类问题的基本思想。
思路
前面说了分治思想。那么具体如何分解问题呢。
思路就是把大文件分割成多个可以内存处理的小文件,对每个小文件统计top k问题,最后再对所有统计结果合并得到最终的top k。
注意,这里的分割并不是随意分割的,那样最终结果显然是不对的,必须保证相同的ip记录都分割到同一个文件。那么hash算法最合适不过了,可以把相同的ip哈希到同一文件。
关于top k问题,效率高的解法是使用构造最小堆或者借助快速排序的思想,复杂度为O(nlogk)。这里更适合用最小堆,具体来说,就是先利用前k个数据构建一个固定大小k的最小堆,对之后的数据,小于堆顶不做处理,大于则替换堆顶并调整。这样,对每个文件顺序处理完之后就得到最终结果,而不需要保留每个文件的top k再归并。
实现
博主偷懒,借助TreeSet代替最小堆来维护top k数据,TreeSet的话底层是借助红黑树排序,比最小堆复杂些,实际上对每个小文件用红黑树全排序再截取前k个。复杂度O(nlogm),这里m是每个小文件中的数量, m>>k。再有时间的话再用最小堆优化一下,复杂度应为O(nlogk)。
ps:已实现最小堆版本,见实现2,并做了对比实验
定时任务使用quartz实现。
下面是代码。
IP类,封装ip计数,使用TreeSet存放须实现comparable接口。注意这里重写compare方法不要return 0,否则会被TreeSet视为相同对象而放不进去。这个可以看一下TreeSet的实现,它实际上内部还是一个TreeMap,只是把对象作为key,而value没有使用。add添加元素时,会调用TreeMap的put方法,put内部又会调用compare方法,如果compare返回结果为0,只是重新setValue,对TreeSet相当于什么也没做。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
| package com.hellolvs;
import org.apache.commons.lang3.builder.ToStringBuilder;
public class IP implements Comparable<IP> {
private String ip;
private int count;
public IP() {
}
public IP(String ip, int count) {
this.ip = ip;
this.count = count;
}
public String getIp() {
return ip;
}
public void setIp(String ip) {
this.ip = ip;
}
public int getCount() {
return count;
}
public void setCount(int count) {
this.count = count;
}
@Override
public int compareTo(IP o) {
return o.count < this.count ? -1 : 1;
}
@Override
public String toString() {
return ToStringBuilder.reflectionToString(this);
}
}
|
IPCountJob类,定时统计日志文件中top k个ip。
注意其中的分割文件,这里的分割需要对文件边读边写,不能一次性读入内存再分割。guava io的readLines是直接装入内存的,所以不能用。可以使用java原生的io类,或使用commons io的LineIterator更优雅一些。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
| package com.hellolvs;
import com.google.common.base.Charsets;
import com.google.common.base.Objects;
import com.google.common.base.StandardSystemProperty;
import com.google.common.collect.Maps;
import com.google.common.collect.Sets;
import com.google.common.io.Files;
import com.google.common.io.LineProcessor;
import org.apache.commons.io.FileUtils;
import org.apache.commons.io.LineIterator;
import org.quartz.Job;
import org.quartz.JobExecutionContext;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.nio.charset.Charset;
import java.security.SecureRandom;
import java.util.HashMap;
import java.util.Map;
import java.util.TreeSet;
import java.util.concurrent.atomic.AtomicInteger;
public class IPCountJob implements Job {
private static final Logger LOG = LoggerFactory.getLogger(IPCountJob.class);
private static final String LINE_SEPARATOR = StandardSystemProperty.LINE_SEPARATOR.value();
private static final Charset UTF_8 = Charsets.UTF_8;
private static final String INPUT_PATH = "/home/lvs/logs/ip.log";
private static final String OUTPUT_PATH = "/home/lvs/logs/split/";
private static final int SPLIT_NUM = 1024;
private static final int TOP_K = 100;
private TreeSet<IP> resultSet = Sets.newTreeSet();
private final Map<Integer, BufferedWriter> bufferMap = Maps.newHashMapWithExpectedSize(SPLIT_NUM);
@Override
public void execute(JobExecutionContext jobExecutionContext) {
try {
execute();
} catch (Exception e) {
LOG.error("定时任务出错:{}", e.getMessage(), e);
}
}
public void execute() throws IOException {
File ipLogFile = new File(INPUT_PATH);
splitLog(ipLogFile, SPLIT_NUM);
File logSplits = new File(OUTPUT_PATH);
for (File logSplit : logSplits.listFiles()) {
countTopK(logSplit, TOP_K);
}
LOG.info("结果集:{}", resultSet.size());
for (IP ip : resultSet) {
LOG.info("{}", ip);
}
}
public static void generateLog(long logNum) throws IOException {
File log = new File(INPUT_PATH);
File parentDir = log.getParentFile();
if (!parentDir.exists()) {
parentDir.mkdirs();
}
log.createNewFile();
SecureRandom random = new SecureRandom();
try (BufferedWriter bw = new BufferedWriter(new FileWriter(log))) {
for (int i = 0; i < logNum; i++) {
StringBuilder sb = new StringBuilder();
sb.append("192.").append(random.nextInt(255)).append(".").append(random.nextInt(255)).append(".")
.append(random.nextInt(255)).append(LINE_SEPARATOR);
bw.write(sb.toString());
}
bw.flush();
}
}
private void splitLog(File logFile, int fileNum) throws IOException {
for (int i = 0; i < fileNum; i++) {
File file = new File(OUTPUT_PATH + i);
File parentDir = file.getParentFile();
if (!parentDir.exists()) {
parentDir.mkdirs();
}
bufferMap.put(i, new BufferedWriter(new FileWriter(file)));
}
LineIterator it = null;
try {
it = FileUtils.lineIterator(logFile, "UTF-8");
while (it.hasNext()) {
String ip = it.nextLine();
int hashCode = Objects.hashCode(ip);
hashCode = hashCode < 0 ? -hashCode : hashCode;
BufferedWriter writer = bufferMap.get(hashCode % fileNum);
writer.write(ip + LINE_SEPARATOR);
}
} finally {
LineIterator.closeQuietly(it);
for (Map.Entry<Integer, BufferedWriter> buffer : bufferMap.entrySet()) {
BufferedWriter writer = buffer.getValue();
writer.flush();
writer.close();
}
bufferMap.clear();
}
}
private void countTopK(File logSplit, int k) throws IOException {
HashMap<String, AtomicInteger> ipCountMap = Files.readLines(logSplit, UTF_8,
new LineProcessor<HashMap<String, AtomicInteger>>() {
private HashMap<String, AtomicInteger> ipCountMap = Maps.newHashMap();
@Override
public boolean processLine(String line) throws IOException {
AtomicInteger ipCount = ipCountMap.get(line.trim());
if (ipCount != null) {
ipCount.getAndIncrement();
} else {
ipCountMap.put(line.trim(), new AtomicInteger(1));
}
return true;
}
@Override
public HashMap<String, AtomicInteger> getResult() {
return ipCountMap;
}
});
for (Map.Entry<String, AtomicInteger> entry : ipCountMap.entrySet()) {
resultSet.add(new IP(entry.getKey(), entry.getValue().get()));
}
TreeSet<IP> temp = Sets.newTreeSet();
int i = 0;
for (IP o : resultSet) {
temp.add(o);
i++;
if (i >= k) {
break;
}
}
resultSet = temp;
}
public TreeSet<IP> getResult() {
return resultSet;
}
}
|
Main,定时任务启动
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| package com.hellolvs;
import org.quartz.JobBuilder;
import org.quartz.JobDetail;
import org.quartz.Scheduler;
import org.quartz.SimpleScheduleBuilder;
import org.quartz.Trigger;
import org.quartz.TriggerBuilder;
import org.quartz.impl.StdSchedulerFactory;
public class Main {
public static void main(String[] args) throws Exception {
IPCountJob.generateLog(600000000);
JobDetail job = JobBuilder.newJob(IPCountJob.class)
.withIdentity("ipCountJob", "group1").build();
Trigger trigger = TriggerBuilder
.newTrigger()
.withIdentity("ipCountTrigger", "group1")
.withSchedule(
SimpleScheduleBuilder.simpleSchedule()
.withIntervalInMinutes(10).repeatForever())
.build();
Scheduler scheduler = new StdSchedulerFactory().getScheduler();
scheduler.start();
scheduler.scheduleJob(job, trigger);
}
}
|
实现2
IP类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
| package com.hellolvs;
import org.apache.commons.lang3.builder.ToStringBuilder;
public class IP implements Comparable<IP> {
private String ip;
private int count;
public IP() {
}
public IP(String ip, int count) {
this.ip = ip;
this.count = count;
}
public String getIp() {
return ip;
}
public void setIp(String ip) {
this.ip = ip;
}
public int getCount() {
return count;
}
public void setCount(int count) {
this.count = count;
}
@Override
public int compareTo(IP o) {
return Integer.compare(this.count, o.count);
}
@Override
public String toString() {
return ToStringBuilder.reflectionToString(this);
}
}
|
IPCountJob类,最小堆版本统计top k
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
| package com.hellolvs;
import com.google.common.base.Charsets;
import com.google.common.base.Objects;
import com.google.common.base.StandardSystemProperty;
import com.google.common.collect.Lists;
import com.google.common.collect.Maps;
import com.google.common.io.Files;
import com.google.common.io.LineProcessor;
import org.apache.commons.io.FileUtils;
import org.apache.commons.io.LineIterator;
import org.quartz.Job;
import org.quartz.JobExecutionContext;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.nio.charset.Charset;
import java.security.SecureRandom;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.concurrent.atomic.AtomicInteger;
public class IPCountJob implements Job {
private static final Logger LOG = LoggerFactory.getLogger(IPCountJob.class);
private static final String LINE_SEPARATOR = StandardSystemProperty.LINE_SEPARATOR.value();
private static final Charset UTF_8 = Charsets.UTF_8;
private static final String INPUT_PATH = "/home/lvs/logs/ip.log";
private static final String OUTPUT_PATH = "/home/lvs/logs/split/";
private static final int SPLIT_NUM = 1024;
private static final int TOP_K = 100;
private List<IP> result = Lists.newArrayListWithExpectedSize(TOP_K);
private final Map<Integer, BufferedWriter> bufferMap = Maps.newHashMapWithExpectedSize(SPLIT_NUM);
@Override
public void execute(JobExecutionContext jobExecutionContext) {
try {
execute();
} catch (Exception e) {
LOG.error("定时任务出错:{}", e.getMessage(), e);
}
}
public void execute() throws IOException {
File ipLogFile = new File(INPUT_PATH);
splitLog(ipLogFile, SPLIT_NUM);
File logSplits = new File(OUTPUT_PATH);
for (File logSplit : logSplits.listFiles()) {
countTopK(logSplit, TOP_K);
}
MinHeap.sort(result);
LOG.info("结果集:{}", result.size());
for (int i = result.size() - 1; i >= 0; i--) {
LOG.info("{}", result.get(i));
}
}
public static void generateLog(long logNum) throws IOException {
File log = new File(INPUT_PATH);
File parentDir = log.getParentFile();
if (!parentDir.exists()) {
parentDir.mkdirs();
}
log.createNewFile();
SecureRandom random = new SecureRandom();
try (BufferedWriter bw = new BufferedWriter(new FileWriter(log))) {
for (int i = 0; i < logNum; i++) {
StringBuilder sb = new StringBuilder();
sb.append("192.").append(random.nextInt(255)).append(".").append(random.nextInt(255)).append(".")
.append(random.nextInt(255)).append(LINE_SEPARATOR);
bw.write(sb.toString());
}
bw.flush();
}
}
private void splitLog(File logFile, int fileNum) throws IOException {
for (int i = 0; i < fileNum; i++) {
File file = new File(OUTPUT_PATH + i);
File parentDir = file.getParentFile();
if (!parentDir.exists()) {
parentDir.mkdirs();
}
bufferMap.put(i, new BufferedWriter(new FileWriter(file)));
}
LineIterator it = null;
try {
it = FileUtils.lineIterator(logFile, "UTF-8");
while (it.hasNext()) {
String ip = it.nextLine();
int hashCode = Objects.hashCode(ip);
hashCode = hashCode < 0 ? -hashCode : hashCode;
BufferedWriter writer = bufferMap.get(hashCode % fileNum);
writer.write(ip + LINE_SEPARATOR);
}
} finally {
LineIterator.closeQuietly(it);
for (Map.Entry<Integer, BufferedWriter> buffer : bufferMap.entrySet()) {
BufferedWriter writer = buffer.getValue();
writer.flush();
writer.close();
}
bufferMap.clear();
}
}
private void countTopK(File logSplit, int k) throws IOException {
HashMap<String, AtomicInteger> ipCountMap = Files.readLines(logSplit, UTF_8,
new LineProcessor<HashMap<String, AtomicInteger>>() {
private HashMap<String, AtomicInteger> ipCountMap = Maps.newHashMap();
@Override
public boolean processLine(String line) throws IOException {
AtomicInteger ipCount = ipCountMap.get(line.trim());
if (ipCount != null) {
ipCount.getAndIncrement();
} else {
ipCountMap.put(line.trim(), new AtomicInteger(1));
}
return true;
}
@Override
public HashMap<String, AtomicInteger> getResult() {
return ipCountMap;
}
});
for (Map.Entry<String, AtomicInteger> entry : ipCountMap.entrySet()) {
IP ip = new IP(entry.getKey(), entry.getValue().get());
if (result.size() != k) {
result.add(ip);
if (result.size() == k) {
MinHeap.initMinHeap(result);
}
} else {
if (ip.compareTo(result.get(0)) > 0) {
result.set(0, ip);
MinHeap.adjust(result, 0, k);
}
}
}
}
public List<IP> getResult() {
return result;
}
}
|
MinHeap类,最小堆工具
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
| package com.hellolvs;
import java.util.List;
public class MinHeap {
public static <T extends Comparable<? super T>> void sort(List<T> list) {
for (int i = list.size() - 1; i > 0; i--) {
swap(list, 0, i);
adjust(list, 0, i);
}
}
public static <T extends Comparable<? super T>> void initMinHeap(List<T> list) {
for (int i = list.size() / 2 - 1; i >= 0; i--) {
adjust(list, i, list.size());
}
}
public static <T extends Comparable<? super T>> void adjust(List<T> list, int cur, int length) {
T tmp = list.get(cur);
for (int i = 2 * cur + 1; i < length; i = 2 * i + 1) {
if (i + 1 < length && list.get(i).compareTo(list.get(i + 1)) > 0) {
i++;
}
if (tmp.compareTo(list.get(i)) > 0) {
list.set(cur, list.get(i));
cur = i;
} else {
break;
}
}
list.set(cur, tmp);
}
private static <T extends Comparable<? super T>> void swap(List<T> list, int i, int j) {
T tmp = list.get(i);
list.set(i, list.get(j));
list.set(j, tmp);
}
}
|
Main类,无改动
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| package com.hellolvs;
import org.quartz.JobBuilder;
import org.quartz.JobDetail;
import org.quartz.Scheduler;
import org.quartz.SimpleScheduleBuilder;
import org.quartz.Trigger;
import org.quartz.TriggerBuilder;
import org.quartz.impl.StdSchedulerFactory;
public class Main {
public static void main(String[] args) throws Exception {
IPCountJob.generateLog(600000000);
JobDetail job = JobBuilder.newJob(IPCountJob.class)
.withIdentity("ipCountJob", "group1").build();
Trigger trigger = TriggerBuilder
.newTrigger()
.withIdentity("ipCountTrigger", "group1")
.withSchedule(
SimpleScheduleBuilder.simpleSchedule()
.withIntervalInMinutes(10).repeatForever())
.build();
Scheduler scheduler = new StdSchedulerFactory().getScheduler();
scheduler.start();
scheduler.scheduleJob(job, trigger);
}
}
|
附
附一下pom文件:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
| <?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.hellolvs</groupId>
<artifactId>ipCount</artifactId>
<version>1.0.0</version>
<packaging>jar</packaging>
<properties>
<guava.version>20.0</guava.version>
<commons-lang3.version>3.1</commons-lang3.version>
<commons-io.version>2.4</commons-io.version>
<joda-time.version>2.6</joda-time.version>
<org.quartz-scheduler.version>2.1.7</org.quartz-scheduler.version>
<org.slf4j.version>1.7.5</org.slf4j.version>
<logback.version>1.0.13</logback.version>
<junit.version>4.10</junit.version>
<java.version>1.8</java.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>${guava.version}</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>${commons-lang3.version}</version>
</dependency>
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>${commons-io.version}</version>
</dependency>
<dependency>
<groupId>joda-time</groupId>
<artifactId>joda-time</artifactId>
<version>${joda-time.version}</version>
</dependency>
<dependency>
<groupId>org.quartz-scheduler</groupId>
<artifactId>quartz</artifactId>
<version>${org.quartz-scheduler.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${org.slf4j.version}</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>${logback.version}</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-core</artifactId>
<version>${logback.version}</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit-dep</artifactId>
<version>${junit.version}</version>
<scope>test</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
</dependency>
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
</dependency>
<dependency>
<groupId>joda-time</groupId>
<artifactId>joda-time</artifactId>
</dependency>
<dependency>
<groupId>org.quartz-scheduler</groupId>
<artifactId>quartz</artifactId>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-core</artifactId>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit-dep</artifactId>
</dependency>
</dependencies>
<build>
<finalName>ROOT</finalName>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>${java.version}</source>
<target>${java.version}</target>
<encoding>${project.build.sourceEncoding}</encoding>
</configuration>
</plugin>
</plugins>
</build>
</project>
|
对比实验
生成了6亿条数据的日志。
TreeSet版本:
1
2
3
4
| 生成6亿条日志时间:521582
分割文件时间:173219
分割后统计top k时间:195037
定时任务执行时间:368294
|
注:定时任务执行时间指的是对大文件的总统计时间,主要是分割文件+分割后统计top k。
cpu和堆使用情况:
可以看到堆变化明显分为三阶段:对应了生成日志、分割日志、分割后统计top k。
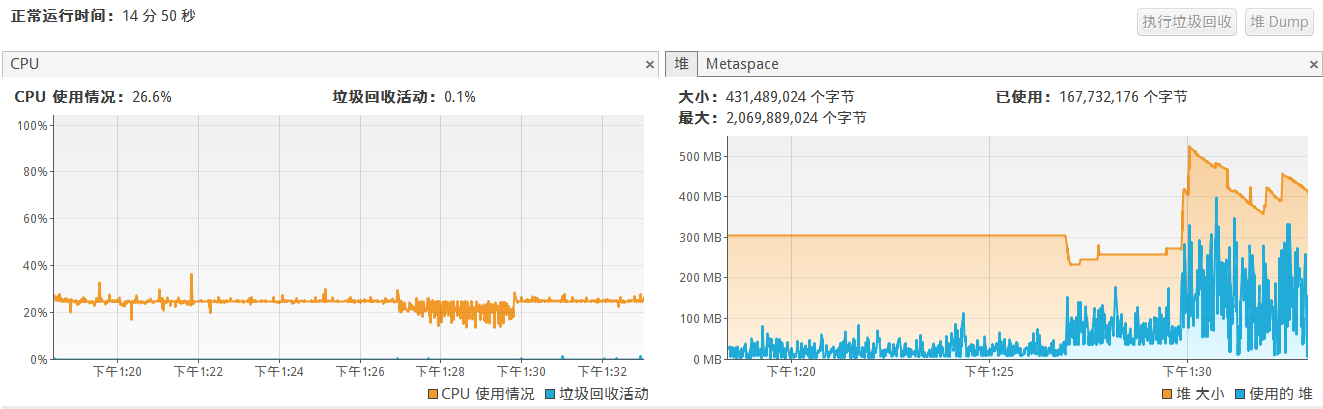
最小堆版本:
1
2
3
4
| 生成6亿条日志时间:513840
分割文件时间:148861
分割后统计top k时间:190966
定时任务执行时间:339870
|
cpu和堆使用情况:
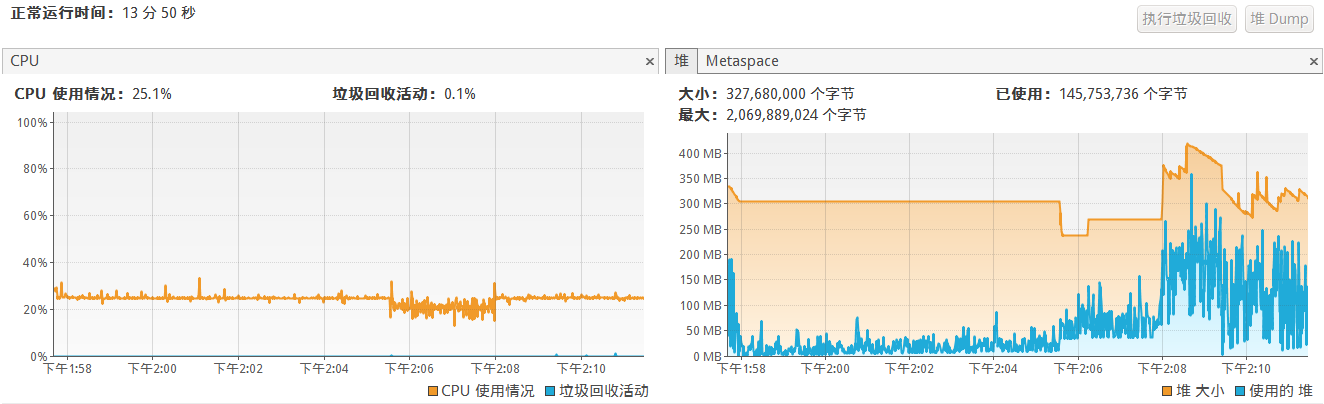
总结:
生成日志和分割文件是没有改动的,运行时间不一样,可能有一定误差。
倒是两个版本统计top k时间没有明显的变化,按上面分析O(nlogm)和O(nlogk)应该有比较明显的差距才对,这里n=600000000,m约600000,k=100,各位可以帮忙分析一下效率差距不大的原因。
不过可以看到堆内存使用明显降低了约100MB,因为TreeSet需要添加m个元素再截取k个,而MinHeap只需要添加k个元素。