由于标题长度限制,原题是这样:某系统QPS100万,每十分钟统计一下请求次数最多的100个IP。ip请求写到日志的话,其实就是超大文件中统计top k问题。10分钟6亿条记录,大约是10G级别,所以对于一般单机处理来讲不能一次性加载到内存计算。所以分治算法是处理这类问题的基本思想。
思路
前面说了分治思想。那么具体如何分解问题呢。
思路就是把大文件分割成多个可以内存处理的小文件,对每个小文件统计top k问题,最后再对所有统计结果合并得到最终的top k。
注意,这里的分割并不是随意分割的,那样最终结果显然是不对的,必须保证相同的ip记录都分割到同一个文件。那么hash算法最合适不过了,可以把相同的ip哈希到同一文件。
关于top k问题,效率高的解法是使用构造最小堆或者借助快速排序的思想,复杂度为O(nlogk)。这里更适合用最小堆,具体来说,就是先利用前k个数据构建一个固定大小k的最小堆,对之后的数据,小于堆顶不做处理,大于则替换堆顶并调整。这样,对每个文件顺序处理完之后就得到最终结果,而不需要保留每个文件的top k再归并。
实现
博主偷懒,借助TreeSet代替最小堆来维护top k数据,TreeSet的话底层是借助红黑树排序,比最小堆复杂些,实际上对每个小文件用红黑树全排序再截取前k个。复杂度O(nlogm),这里m是每个小文件中的数量, m>>k。再有时间的话再用最小堆优化一下,复杂度应为O(nlogk)。
ps:已实现最小堆版本,见实现2,并做了对比实验
定时任务使用quartz实现。
下面是代码。
IP类,封装ip计数,使用TreeSet存放须实现comparable接口。注意这里重写compare方法不要return 0,否则会被TreeSet视为相同对象而放不进去。这个可以看一下TreeSet的实现,它实际上内部还是一个TreeMap,只是把对象作为key,而value没有使用。add添加元素时,会调用TreeMap的put方法,put内部又会调用compare方法,如果compare返回结果为0,只是重新setValue,对TreeSet相当于什么也没做。
1 | package com.hellolvs; |
IPCountJob类,定时统计日志文件中top k个ip。
注意其中的分割文件,这里的分割需要对文件边读边写,不能一次性读入内存再分割。guava io的readLines是直接装入内存的,所以不能用。可以使用java原生的io类,或使用commons io的LineIterator更优雅一些。
1 | package com.hellolvs; |
Main,定时任务启动
1 | package com.hellolvs; |
实现2
IP类
1 | package com.hellolvs; |
IPCountJob类,最小堆版本统计top k
1 | package com.hellolvs; |
MinHeap类,最小堆工具
1 | package com.hellolvs; |
Main类,无改动
1 | package com.hellolvs; |
附
附一下pom文件:
1 |
|
对比实验
生成了6亿条数据的日志。
TreeSet版本:
1 | 生成6亿条日志时间:521582 |
注:定时任务执行时间指的是对大文件的总统计时间,主要是分割文件+分割后统计top k。
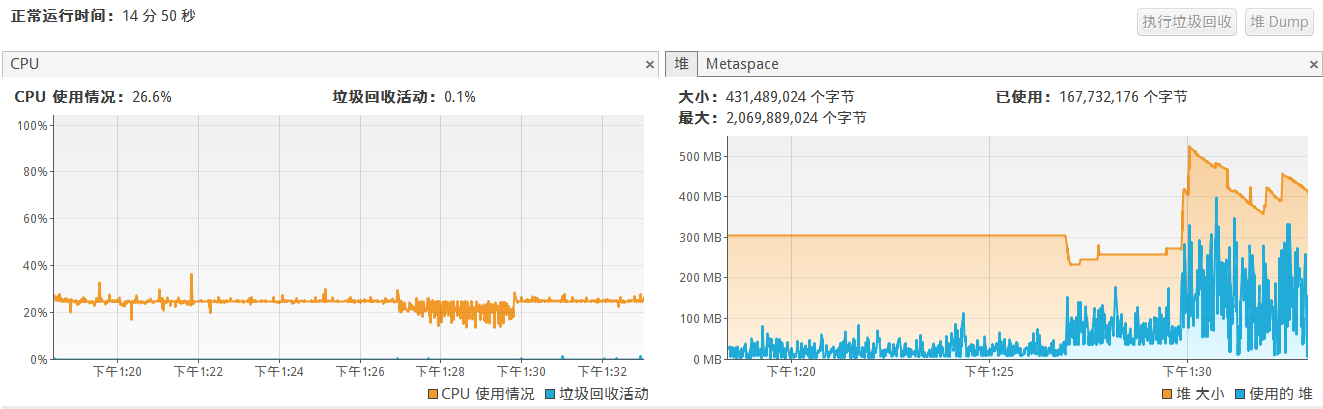
cpu和堆使用情况:
可以看到堆变化明显分为三阶段:对应了生成日志、分割日志、分割后统计top k。
最小堆版本:
1 | 生成6亿条日志时间:513840 |
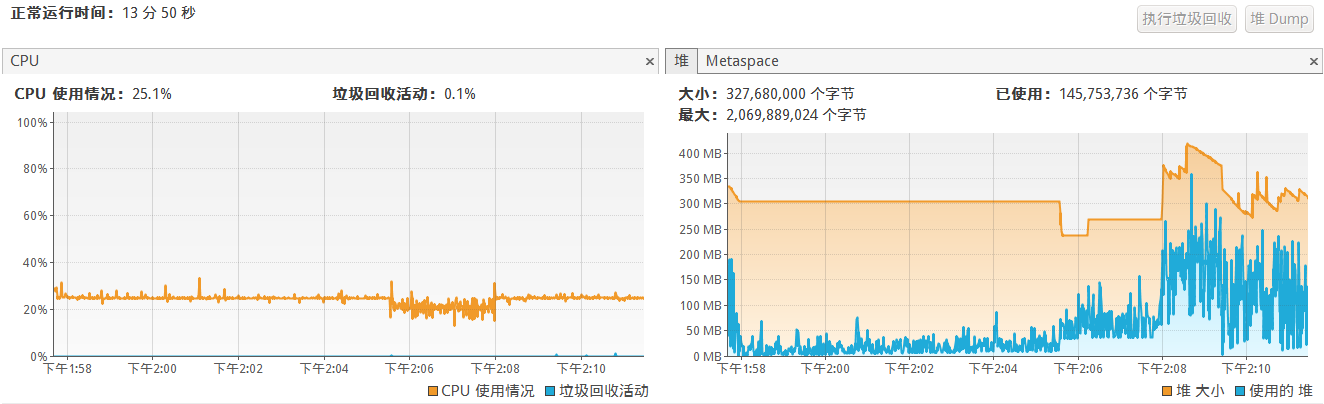
cpu和堆使用情况:
总结:
生成日志和分割文件是没有改动的,运行时间不一样,可能有一定误差。
倒是两个版本统计top k时间没有明显的变化,按上面分析O(nlogm)和O(nlogk)应该有比较明显的差距才对,这里n=600000000,m约600000,k=100,各位可以帮忙分析一下效率差距不大的原因。
不过可以看到堆内存使用明显降低了约100MB,因为TreeSet需要添加m个元素再截取k个,而MinHeap只需要添加k个元素。

